
Sportvorhersagen
Ladevorgang...
Ladevorgang...
Die Angabe von Wahrscheinlichkeiten ist ein Kernmerkmal moderner KI-gestützter Sportwetten-Prognosen. Statt einfach zu behaupten, dass ein Team gewinnen wird, liefern seriöse Systeme differenzierte Aussagen: Team A gewinnt mit 58 Prozent Wahrscheinlichkeit, ein Unentschieden ist zu 24 Prozent wahrscheinlich, Team B gewinnt zu 18 Prozent. Diese probabilistischen Aussagen sind informativer als binäre Vorhersagen, erfordern aber ein gewisses Verständnis, um sie richtig zu interpretieren und für Wettentscheidungen zu nutzen.
Die Verwendung von Wahrscheinlichkeiten in Prognosen ist keine bloße Spielerei, sondern eine fundamentale Notwendigkeit. Fußballspiele sind von Natur aus unsicher, und jede Vorhersage, die absolute Sicherheit vorgibt, ist unehrlich. Die Angabe von Wahrscheinlichkeiten macht diese Unsicherheit explizit und ermöglicht einen rationaleren Umgang mit Prognosen. Nutze mathematisch fundierte AI Champions League Tipps, um dein Risiko zu minimieren. Wer versteht, dass eine 60-prozentige Siegwahrscheinlichkeit bedeutet, dass das Team in vier von zehn vergleichbaren Situationen nicht gewinnt, wird seine Erwartungen entsprechend kalibrieren.
Was bedeuten Wahrscheinlichkeiten bei Spielprognosen?
Eine Wahrscheinlichkeit von 60 Prozent für einen Heimsieg bedeutet nicht, dass der Heimsieg sicher ist. Sie bedeutet, dass unter den Annahmen des Modells in 60 von 100 vergleichbaren Situationen der Heimsieg eintreten würde. In den übrigen 40 Situationen würde das Spiel anders ausgehen. Diese Interpretation ist fundamental für das Verständnis probabilistischer Prognosen.
Die Umrechnung von Wahrscheinlichkeiten in erwartete Häufigkeiten hilft bei der Intuition. Wenn ein Modell zehn Spielen jeweils eine 70-prozentige Siegwahrscheinlichkeit für die Favoriten zuweist, sollte man erwarten, dass etwa sieben dieser Favoriten tatsächlich gewinnen. Wenn alle zehn gewinnen oder nur drei, stimmt etwas mit den Prognosen oder mit den Erwartungen nicht.
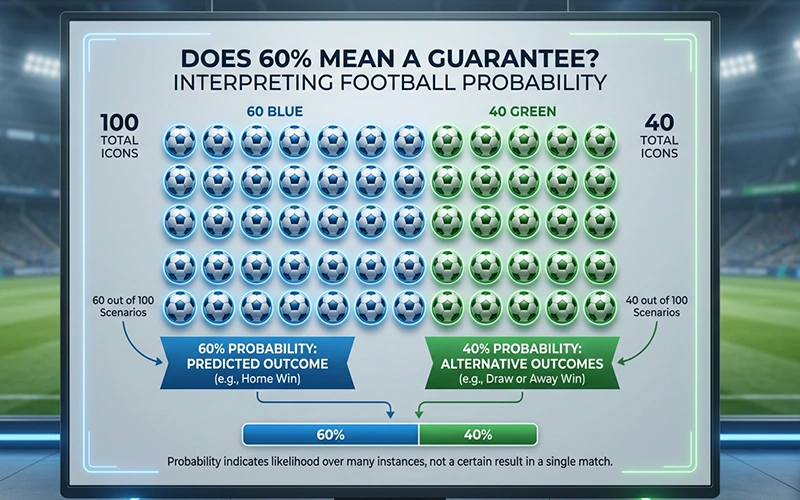
Die Kalibrierung von Prognosen ist ein technischer Begriff für die Frage, ob die angegebenen Wahrscheinlichkeiten der Realität entsprechen. Ein gut kalibriertes Modell produziert bei Spielen, denen es eine 70-prozentige Siegwahrscheinlichkeit zuweist, tatsächlich etwa 70 Prozent Siege. Schlecht kalibrierte Modelle über- oder unterschätzen die Wahrscheinlichkeiten systematisch.
Die Überprüfung der Kalibrierung erfordert große Stichproben. Ein einzelnes Spiel sagt nichts über die Qualität der Prognose aus, weil auch ein 90-Prozent-Favorit gelegentlich verliert. Erst über Hunderte von Vorhersagen zeigt sich, ob die Wahrscheinlichkeitsangaben akkurat sind. Diese langfristige Perspektive ist essenziell für die Bewertung von Prognosesystemen.
Die Berechnung von Wahrscheinlichkeiten in KI-Modellen
KI-Systeme für Champions-League-Prognosen berechnen Wahrscheinlichkeiten auf verschiedene Weisen. Das Verständnis dieser Methoden hilft bei der Einordnung der Ergebnisse.
Statistische Modelle wie die Poisson-Regression liefern direkt Wahrscheinlichkeiten für verschiedene Toranzahlen. Aus der Verteilung der erwarteten Tore für beide Teams ergeben sich die Wahrscheinlichkeiten für Heimsieg, Unentschieden und Auswärtssieg. Diese Berechnung ist mathematisch transparent und nachvollziehbar.
Simulationsbasierte Ansätze ermitteln Wahrscheinlichkeiten durch wiederholtes virtuelles Durchspielen des Spiels. Wenn von 10.000 Simulationen 5.800 mit einem Heimsieg enden, beträgt die geschätzte Wahrscheinlichkeit 58 Prozent. Die Präzision steigt mit der Anzahl der Simulationen.
Machine-Learning-Modelle können ebenfalls Wahrscheinlichkeiten ausgeben, wobei die Interpretation komplexer ist. Klassifikationsmodelle wie logistische Regression oder neuronale Netze mit Softmax-Ausgabe liefern Wahrscheinlichkeitsschätzungen, deren Kalibrierung allerdings nicht automatisch gegeben ist und oft nachträglich adjustiert werden muss.
Die Ensemble-Methode kombiniert die Wahrscheinlichkeiten verschiedener Modelle zu einer Gesamtprognose. Wenn drei Modelle Heimsiegwahrscheinlichkeiten von 55, 60 und 58 Prozent liefern, könnte der Durchschnitt von etwa 58 Prozent als robustere Schätzung dienen. Die Kombination verschiedener Perspektiven reduziert die Abhängigkeit von einzelnen Modellannahmen.
Die Interpretation von Wahrscheinlichkeitsdifferenzen
Nicht alle Wahrscheinlichkeitsangaben sind gleich aussagekräftig. Die Differenz zwischen einer 55-prozentigen und einer 60-prozentigen Siegwahrscheinlichkeit mag klein erscheinen, hat aber praktische Konsequenzen.
Kleine Unterschiede in den Wahrscheinlichkeiten können große Unterschiede in den fairen Quoten bedeuten. Eine Wahrscheinlichkeit von 50 Prozent entspricht einer fairen Quote von 2,00, während 55 Prozent einer Quote von etwa 1,82 entsprechen. Diese Differenz von 18 Prozent in der Quote kann den Unterschied zwischen einer profitablen und einer unprofitablen Wette ausmachen.
Die Unsicherheit der Wahrscheinlichkeitsschätzung muss berücksichtigt werden. Wenn ein Modell eine Siegwahrscheinlichkeit von 58 Prozent ausgibt, aber das Konfidenzintervall von 50 bis 66 Prozent reicht, ist die Schätzung mit erheblicher Unsicherheit behaftet. In solchen Fällen sollte man vorsichtiger agieren als bei engeren Konfidenzintervallen.
Die Differenz zwischen eigener Einschätzung und Marktquote ist der zentrale Indikator für Value. Wenn das eigene Modell eine 60-prozentige Wahrscheinlichkeit schätzt und die Marktquote eine 50-prozentige impliziert, besteht ein theoretischer Vorteil. Ob dieser Vorteil real ist, hängt von der Qualität der eigenen Schätzung ab.
Die Umrechnung zwischen Quoten und Wahrscheinlichkeiten

Das Verständnis der Beziehung zwischen Quoten und Wahrscheinlichkeiten ist fundamental für jeden, der mit probabilistischen Prognosen arbeitet.
Die Grundformel für Dezimalquoten ist einfach: Wahrscheinlichkeit gleich eins geteilt durch Quote. Eine Quote von 2,00 entspricht einer Wahrscheinlichkeit von 50 Prozent, eine Quote von 4,00 entspricht 25 Prozent, und so weiter. Diese Umrechnung ermöglicht den direkten Vergleich zwischen Modellprognosen und Marktquoten.
Die Buchmacher-Marge kompliziert die Sache. Die Quoten der Buchmacher reflektieren nicht die wahren Wahrscheinlichkeiten, sondern enthalten einen Aufschlag zugunsten des Anbieters. Die Summe der impliziten Wahrscheinlichkeiten für alle Ausgänge übersteigt 100 Prozent, typischerweise um 5 bis 10 Prozentpunkte. Diese Marge muss bei Vergleichen berücksichtigt werden.
Die Extraktion der wahren Wahrscheinlichkeiten aus Marktquoten erfordert eine Normalisierung. Die impliziten Wahrscheinlichkeiten werden durch ihre Summe geteilt, um auf 100 Prozent zu kommen. Das Ergebnis ist eine Schätzung der Marktwahrscheinlichkeiten, die mit den eigenen Prognosen verglichen werden kann.
Der Vergleich zwischen Modell- und Marktwahrscheinlichkeiten identifiziert potenzielle Diskrepanzen. Wenn das eigene Modell eine deutlich andere Wahrscheinlichkeit schätzt als der Markt, könnte das auf einen Value hindeuten, oder es könnte ein Zeichen sein, dass das Modell etwas übersieht, was der Markt weiß.
Die Rolle der Unsicherheit in Prognosen
Jede Wahrscheinlichkeitsangabe ist selbst mit Unsicherheit behaftet. Diese Meta-Unsicherheit zu verstehen ist wichtig für einen angemessenen Umgang mit Prognosen.
Die Modellunischerheit entsteht aus den Annahmen und Vereinfachungen, die jedes Modell macht. Verschiedene Modelle können für dasselbe Spiel unterschiedliche Wahrscheinlichkeiten liefern, und keines davon ist definitiv korrekt. Die Spannbreite der Modellschätzungen gibt einen Hinweis auf diese Unsicherheit.
Die Datenunischerheit resultiert aus der begrenzten Stichprobe, auf der die Schätzungen basieren. Die Leistungsdaten eines Teams aus zwanzig Spielen erlauben nur eine ungefähre Schätzung seiner wahren Stärke. Die statistischen Konfidenzintervalle quantifizieren diese Unsicherheit.
Die fundamentale Unsicherheit betrifft die inhärente Unvorhersehbarkeit des Fußballs. Selbst wenn Modell und Daten perfekt wären, bliebe das Spielergebnis unsicher, weil Zufallsfaktoren eine Rolle spielen. Diese Unsicherheit lässt sich nicht eliminieren, sondern nur akzeptieren.
Die praktische Konsequenz ist Bescheidenheit. Prognosen sollten als bestmögliche Schätzungen unter Unsicherheit verstanden werden, nicht als sichere Vorhersagen. Die Einsatzplanung sollte diese Unsicherheit widerspiegeln.
Die Anwendung von Wahrscheinlichkeiten auf verschiedene Wettmärkte
Wahrscheinlichkeitsbasierte Prognosen lassen sich auf verschiedene Wettmärkte anwenden, nicht nur auf den einfachen Spielausgang.
Der Drei-Weg-Markt ist die direkteste Anwendung. Die Wahrscheinlichkeiten für Heimsieg, Unentschieden und Auswärtssieg lassen sich direkt mit den angebotenen Quoten vergleichen. Die Differenz zwischen impliziter Quotenwahrscheinlichkeit und Modellwahrscheinlichkeit zeigt potenzielle Value-Wetten an.
Der Über/Unter-Markt erfordert die Berechnung der Wahrscheinlichkeit, dass die Gesamttoranzahl einen bestimmten Schwellenwert überschreitet. Aus der Verteilung der erwarteten Tore lässt sich diese Wahrscheinlichkeit ableiten und mit der Quote für Über oder Unter vergleichen.
Der Markt für Beide Teams treffen basiert auf der Wahrscheinlichkeit, dass beide Mannschaften mindestens ein Tor erzielen. Diese Wahrscheinlichkeit ergibt sich aus den individuellen Torwahrscheinlichkeiten beider Teams und kann mit der entsprechenden Quote verglichen werden.
Handicap-Wetten erfordern die Berechnung der Wahrscheinlichkeit für verschiedene Tordifferenzen. Die Verteilung der erwarteten Tordifferenz liefert die Grundlage für die Bewertung asiatischer Handicaps.
Die Kalibrierung von Prognosemodellen
Die Kalibrierung ist ein zentrales Qualitätsmerkmal für Modelle, die Wahrscheinlichkeiten ausgeben. Ein gut kalibriertes Modell produziert Wahrscheinlichkeiten, die der tatsächlichen Häufigkeit der Ereignisse entsprechen.
Die Überprüfung der Kalibrierung erfolgt durch die Gruppierung von Vorhersagen nach ihren Wahrscheinlichkeiten. Alle Spiele, denen das Modell eine Siegwahrscheinlichkeit zwischen 60 und 70 Prozent zugewiesen hat, werden zusammengefasst, und die tatsächliche Siegquote in dieser Gruppe wird berechnet. Idealerweise liegt diese Quote nahe bei 65 Prozent.
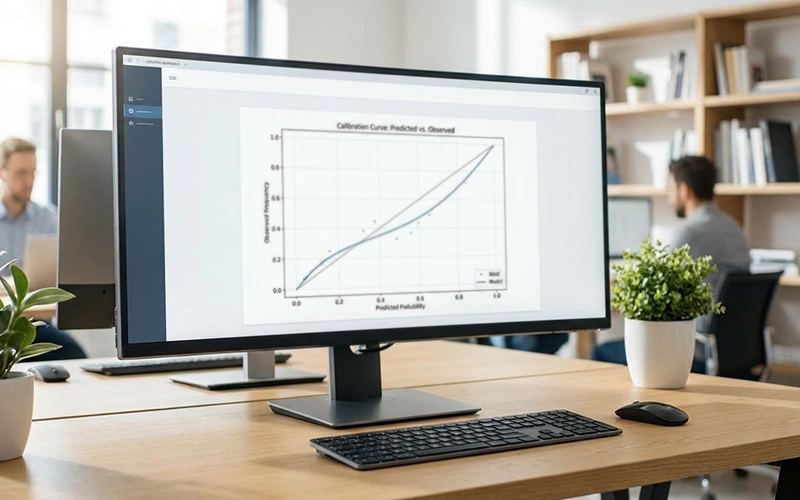
Die Kalibrierungskurve visualisiert die Beziehung zwischen vorhergesagten und beobachteten Wahrscheinlichkeiten. Eine perfekt kalibrierte Kurve folgt der Diagonalen. Abweichungen nach oben deuten auf Überkonfidenz hin, der Modell schätzt seine Prognosen als sicherer ein, als sie sind. Abweichungen nach unten deuten auf Unterkonfidenz hin.
Die nachträgliche Kalibrierung kann die Prognosequalität verbessern. Wenn bekannt ist, dass ein Modell systematisch zu hohe oder zu niedrige Wahrscheinlichkeiten liefert, können die Rohprognosen entsprechend adjustiert werden. Diese Korrektur setzt allerdings eine ausreichend große Stichprobe historischer Vorhersagen voraus.
Die Kombination von Modellwahrscheinlichkeiten mit anderen Informationen
Modellwahrscheinlichkeiten sind wertvoll, aber sie erfassen nicht alle relevanten Informationen. Die Integration zusätzlicher Erkenntnisse kann die Prognosequalität verbessern.
Aktuelle Nachrichten können die Wahrscheinlichkeitsschätzungen verändern. Wenn kurz vor dem Spiel bekannt wird, dass der beste Stürmer verletzt ausfällt, sollte die Siegwahrscheinlichkeit nach unten korrigiert werden. Diese kurzfristigen Informationen sind in den historischen Daten nicht enthalten und erfordern eine manuelle Anpassung.
Die Marktquoten selbst sind eine Informationsquelle. Wenn der Markt eine deutlich andere Wahrscheinlichkeit impliziert als das eigene Modell, könnte das ein Signal sein, dass der Markt etwas weiß, was das Modell nicht erfasst. Die kluge Strategie berücksichtigt beide Perspektiven.
Die Expertenmeinung kann Modellprognosen ergänzen, sollte sie aber nicht ersetzen. Experten können Faktoren einschätzen, die Modelle nicht erfassen, etwa die Stimmung in der Mannschaft oder die taktische Ausrichtung für ein bestimmtes Spiel. Die Kombination von Modell und Expertise kann leistungsfähiger sein als jede Komponente allein.
Die Gewichtung verschiedener Informationsquellen ist eine Kunst. Wie viel Vertrauen verdient das Modell, wie viel die Marktquoten, wie viel die Expertenmeinung? Diese Frage hat keine allgemeingültige Antwort und hängt von der Qualität der jeweiligen Quellen ab.
Die praktische Nutzung von Wahrscheinlichkeitsprognosen
Wer wahrscheinlichkeitsbasierte KI-Tipps für die Champions League nutzen möchte, sollte einige praktische Aspekte beachten.
Die Identifikation von Value-Wetten ist das Hauptziel. Wenn das eigene Modell eine höhere Wahrscheinlichkeit schätzt als die Marktquote impliziert, besteht theoretisch ein Vorteil. Die systematische Suche nach solchen Diskrepanzen ist der Kern einer datengestützten Wettstrategie.
Die Berücksichtigung der Unsicherheit bei der Einsatzplanung ist essenziell. Ein wichtiger Faktor für diese Prozentsätze sind unsere detaillierten Form-Analysen der Teams. Selbst bei einem scheinbaren Value sollte der Einsatz die Unsicherheit der Schätzung widerspiegeln. Das Kelly-Kriterium bietet einen mathematischen Rahmen für die optimale Einsatzgröße, obwohl in der Praxis oft konservativere Ansätze verwendet werden.
Die Dokumentation aller Wetten ermöglicht die langfristige Auswertung. Welche Wahrscheinlichkeitsschätzungen waren akkurat, welche nicht? Gab es systematische Verzerrungen? Diese Erkenntnisse helfen bei der Verfeinerung des Ansatzes.
Die Disziplin, nur bei echtem Value zu wetten, ist entscheidend. Nicht jedes Spiel bietet eine günstige Gelegenheit, und die Bereitschaft, auszusetzen, wenn kein Value vorliegt, unterscheidet erfolgreiche von erfolglosen Wettenden.
Die Wahl des richtigen Buchmachers kann den Unterschied ausmachen. Verschiedene Anbieter bieten unterschiedliche Quoten, und die Suche nach der besten Quote für eine bestimmte Wette erhöht die potenzielle Rendite. Die Differenz zwischen den besten und schlechtesten Quoten kann mehrere Prozentpunkte betragen.
Die Berücksichtigung der Buchmacher-Marge ist wichtig für die Value-Berechnung. Die Marge reduziert die tatsächliche Auszahlung und muss bei der Beurteilung eines vermeintlichen Vorteils berücksichtigt werden. Ein scheinbarer Value kann durch eine hohe Marge aufgezehrt werden.
Die Psychologie des Wettens mit Wahrscheinlichkeiten
Der rationale Umgang mit Wahrscheinlichkeiten erfordert auch ein Bewusstsein für die psychologischen Fallstricke, die den Wettenden beeinflussen können.
Der Bestätigungsfehler führt dazu, dass Menschen Informationen bevorzugen, die ihre bestehenden Überzeugungen stützen. Wer glaubt, dass ein bestimmtes Team gewinnen wird, neigt dazu, Daten zu suchen, die diese Einschätzung bestätigen, und widersprüchliche Hinweise zu ignorieren. Wahrscheinlichkeitsbasierte Prognosen können diesem Bias entgegenwirken, wenn sie ernst genommen werden.
Die Überschätzung der eigenen Fähigkeiten ist ein weit verbreitetes Phänomen. Viele Wettende glauben, dass sie den Markt schlagen können, obwohl die empirische Evidenz dagegen spricht. Die nüchterne Betrachtung der eigenen historischen Performance hilft, diese Illusion zu korrigieren.
Die Verlustaversion führt dazu, dass Verluste psychologisch stärker wiegen als gleichhohe Gewinne. Diese Asymmetrie kann zu irrationalem Verhalten führen, etwa dem Festhalten an Verlustpositionen in der Hoffnung auf Erholung. Ein regelbasierter Ansatz auf Grundlage von Wahrscheinlichkeiten kann helfen, emotionale Entscheidungen zu vermeiden.
Die Risikowahrnehmung verändert sich nach Gewinnen und Verlusten. Nach einer Gewinnserie neigen Menschen zu mehr Risiko, nach Verlusten zu weniger oder zu verzweifelten Versuchen, das Verlorene zurückzugewinnen. Die konsequente Anwendung der Wahrscheinlichkeitslogik schützt vor diesen Schwankungen.
Die Entwicklung eines persönlichen Prognosesystems
Für engagierte Analysten kann die Entwicklung eines eigenen wahrscheinlichkeitsbasierten Prognosesystems ein lohnendes Unterfangen sein.
Die Auswahl der Eingabevariablen ist der erste Schritt. Welche Daten sollen in das Modell einfließen? Die Qualität der Variablenauswahl bestimmt die Qualität der resultierenden Prognosen. Die Beschränkung auf wenige, aussagekräftige Variablen ist oft besser als die Überfrachtung mit zahllosen Faktoren.
Die Wahl der Modellarchitektur hängt von den Anforderungen ab. Einfache Poisson-Modelle sind transparent und robust, während komplexere Machine-Learning-Ansätze möglicherweise bessere Prognosen liefern, aber schwerer zu interpretieren sind.
Die Kalibrierung und Validierung sind unverzichtbare Schritte. Das Modell muss an historischen Daten getestet werden, wobei die Trennung von Trainings- und Testdaten essenziell ist, um Überanpassung zu vermeiden.
Die kontinuierliche Verbesserung auf Basis neuer Erkenntnisse hält das Modell aktuell. Feedback aus den tatsächlichen Ergebnissen fließt in Anpassungen ein, und neue Datenquellen oder Methoden werden integriert, wenn sie die Prognosequalität verbessern.
Die Grenzen wahrscheinlichkeitsbasierter Prognosen
Trotz ihrer Vorteile haben wahrscheinlichkeitsbasierte Prognosen systematische Grenzen.
Die wahre Wahrscheinlichkeit ist unbekannt. Jede Modellschätzung ist eine Annäherung, und verschiedene Modelle liefern unterschiedliche Ergebnisse. Die Frage, welches Modell die wahren Wahrscheinlichkeiten am besten approximiert, lässt sich nur annäherungsweise durch historische Validierung beantworten.
Die Vergangenheit ist nicht immer ein guter Prädiktor für die Zukunft. Modelle lernen aus historischen Daten, aber Teams verändern sich, Taktiken entwickeln sich weiter, und unvorhergesehene Ereignisse können alles ändern. Die Annahme, dass die Zukunft der Vergangenheit ähnelt, ist notwendig, aber nicht immer zutreffend.
Die inhärente Zufälligkeit des Fußballs bleibt bestehen. Selbst perfekte Wahrscheinlichkeitsschätzungen eliminieren nicht das Risiko. Ein 80-Prozent-Favorit verliert in jedem fünften Spiel, und das ist keine Fehlfunktion des Modells, sondern ein unvermeidlicher Aspekt probabilistischer Vorhersagen.
Die Überanpassung an historische Daten ist ein technisches Problem, das die Prognosequalität beeinträchtigen kann. Ein Modell, das perfekt zu vergangenen Daten passt, versagt möglicherweise bei neuen Daten, weil es zufällige Muster gelernt hat, die sich nicht wiederholen.
Der Umgang mit extremen Wahrscheinlichkeiten
Extreme Wahrscheinlichkeiten, sehr hohe oder sehr niedrige, erfordern besondere Vorsicht bei der Interpretation.
Sehr hohe Wahrscheinlichkeiten wie 90 Prozent oder mehr suggerieren einen fast sicheren Ausgang. Doch auch ein 90-Prozent-Favorit verliert in jedem zehnten Spiel. Bei einer Serie von zehn solchen Spielen ist eine Niederlage statistisch zu erwarten. Die scheinbare Sicherheit ist trügerisch.
Die Überschätzung von Favoriten ist ein bekanntes Phänomen. Modelle und Wettende neigen dazu, die Chancen der Topteams zu überschätzen. Die tatsächliche Häufigkeit von Überraschungen ist oft höher als die Wahrscheinlichkeitsangaben vermuten lassen. Ein gewisser Skeptizismus gegenüber extremen Favoritenquoten ist angebracht.
Sehr niedrige Wahrscheinlichkeiten bedeuten nicht Unmöglichkeit. Eine 5-prozentige Siegwahrscheinlichkeit für den Außenseiter impliziert, dass er in einem von zwanzig vergleichbaren Spielen gewinnen würde. In einer Champions-League-Saison mit vielen Spielen sind solche Überraschungen nicht selten.
Die psychologische Wirkung extremer Wahrscheinlichkeiten sollte nicht unterschätzt werden. Hohe Wahrscheinlichkeiten können zu Übermut führen, niedrige zu vorschnellem Aufgeben. Ein rationaler Umgang erfordert die Anerkennung, dass auch extreme Wahrscheinlichkeiten Unsicherheit beinhalten.
Die Bedeutung der Stichprobengröße
Die Interpretation von Wahrscheinlichkeitsprognosen hängt stark von der Stichprobengröße ab. Einzelne Ergebnisse sind wenig aussagekräftig, erst über viele Spiele zeigen sich Muster.
Die kurzfristige Varianz ist hoch. Über zehn Spiele kann die beobachtete Trefferquote stark von den angegebenen Wahrscheinlichkeiten abweichen, ohne dass das Modell fehlerhaft wäre. Diese Schwankungen sind statistisch normal und sollten nicht zu voreiligen Schlüssen führen.
Die langfristige Konvergenz ist das Ziel. Über Hunderte von Spielen sollten sich die beobachteten Häufigkeiten den angegebenen Wahrscheinlichkeiten annähern, wenn das Modell gut kalibriert ist. Diese Konvergenz erfordert Geduld und die Bereitschaft, kurzfristige Schwankungen zu tolerieren.
Die statistische Signifikanz von Abweichungen lässt sich berechnen. Wenn die beobachtete Trefferquote über 100 Spiele systematisch von den Prognosen abweicht, kann man mit statistischen Tests prüfen, ob diese Abweichung signifikant ist oder im Bereich zufälliger Schwankungen liegt.
Die praktische Konsequenz ist die Notwendigkeit einer langfristigen Perspektive. Einzelne Gewinne oder Verluste sagen wenig über die Qualität des Prognoseansatzes aus. Erst die Bilanz über eine Saison oder länger ermöglicht eine fundierte Bewertung.
Die Wahrscheinlichkeitsverteilung für Endergebnisse
Fortgeschrittene Prognosemodelle liefern nicht nur Wahrscheinlichkeiten für den Drei-Weg-Markt, sondern für jedes mögliche Endergebnis. Diese detaillierten Verteilungen eröffnen zusätzliche Analysemöglichkeiten.

Die Wahrscheinlichkeit für ein spezifisches Ergebnis wie 2:1 oder 0:0 lässt sich aus der gemeinsamen Verteilung der Tore beider Teams berechnen. Diese Werte sind typischerweise klein, das wahrscheinlichste Einzelergebnis liegt oft nur bei 10 bis 15 Prozent, was die Schwierigkeit von Correct-Score-Wetten unterstreicht.
Die kumulierten Wahrscheinlichkeiten für Ergebnisklassen sind informativer. Die Wahrscheinlichkeit für mindestens drei Tore insgesamt ergibt sich aus der Summierung aller Ergebnisse mit drei oder mehr Toren. Diese Aggregation liefert die Grundlage für Über/Unter-Wetten.
Die Analyse der Ergebnisverteilung kann überraschende Einsichten liefern. Manchmal zeigt die Verteilung, dass moderate Ergebnisse wie 1:1 oder 2:1 wahrscheinlicher sind als extreme wie 0:0 oder 4:3. Diese Information kann für die Auswahl von Wettmärkten nützlich sein.
Der Vergleich verschiedener Modelle auf der Ebene der Ergebnisverteilungen ist aufschlussreich. Wenn zwei Modelle ähnliche Siegwahrscheinlichkeiten liefern, aber unterschiedliche Ergebnisverteilungen, haben sie unterschiedliche Annahmen über den Spielverlauf. Diese Unterschiede können für bestimmte Wettmärkte relevant sein.
Die Rolle der Wahrscheinlichkeit bei Live-Wetten
Live-Wetten stellen besondere Anforderungen an wahrscheinlichkeitsbasierte Prognosen, weil sich die Situation im Spielverlauf ändert.
Die Aktualisierung der Wahrscheinlichkeiten in Echtzeit erfordert Modelle, die den aktuellen Spielstand, die verbleibende Zeit und den bisherigen Spielverlauf berücksichtigen. Ein Modell, das nur Vor-Spiel-Prognosen liefert, ist für Live-Wetten ungeeignet.
Der Einfluss des Spielstands auf die Wahrscheinlichkeiten ist erheblich. Ein Team, das nach 60 Minuten mit 2:0 führt, hat eine deutlich höhere Siegwahrscheinlichkeit als vor dem Spiel, selbst wenn es als Außenseiter gestartet war. Die dynamische Anpassung erfasst diese Veränderungen.
Die verbleibende Spielzeit beeinflusst die Volatilität der Wahrscheinlichkeiten. Kurz vor Schluss sind die Wahrscheinlichkeiten stabiler, weil weniger Zeit für Veränderungen bleibt. In der ersten Halbzeit können sich die Einschätzungen noch stark verschieben.
Die Qualität der Live-Daten ist kritisch für Echtzeit-Prognosen. Verzögerungen oder Fehler in den Daten können zu falschen Wahrscheinlichkeitsschätzungen führen. Die Infrastruktur für Live-Wetten muss entsprechend robust sein.
Abschließende Perspektive
Wahrscheinlichkeitsbasierte KI-Tipps für die Champions League bieten einen rationalen Rahmen für Wettentscheidungen. Sie machen die inhärente Unsicherheit explizit und ermöglichen einen systematischen Vergleich zwischen eigener Einschätzung und Marktquoten. Gleichzeitig erfordern sie ein Verständnis dessen, was Wahrscheinlichkeiten bedeuten und wie sie zu interpretieren sind.
Die kluge Nutzung solcher Prognosen erfordert Geduld und Disziplin. Einzelne Spiele sagen wenig über die Qualität der Wahrscheinlichkeitsschätzungen aus, erst über viele Wetten zeigt sich, ob der Ansatz funktioniert. Die Bereitschaft, langfristig zu denken und kurzfristige Schwankungen zu akzeptieren, ist essenziell.
Die Champions League mit ihrer Mischung aus erwartbaren Ergebnissen und spektakulären Überraschungen ist ein ideales Testfeld für probabilistische Prognosen. Die großen Favoriten setzen sich oft durch, aber nicht immer. Die Kunst besteht darin, diese Unsicherheit zu akzeptieren und sie für fundierte Entscheidungen zu nutzen.
Abschließend sei betont, dass keine Prognose, wie ausgeklügelt sie auch sein mag, das Risiko eliminieren kann. Wahrscheinlichkeiten quantifizieren Unsicherheit, sie beseitigen sie nicht. Wer das versteht und verantwortungsvoll mit seinem Budget umgeht, kann von wahrscheinlichkeitsbasierten Analysen profitieren. Wer sich von hohen Wahrscheinlichkeitsangaben zu unvorsichtigen Einsätzen verleiten lässt, wird die Grenzen dieses Ansatzes schmerzlich erfahren.