Sportvorhersagen
Ladevorgang...
Ladevorgang...
Die statistische Analyse von Fußballspielen hat in den vergangenen Jahren einen bemerkenswerten Aufschwung erlebt. Was einst das Terrain von Mathematikern und Akademikern war, ist heute ein fester Bestandteil der Sportwettenlandschaft. Für die Champions League bieten statistische Methoden einen systematischen Rahmen, um die Wahrscheinlichkeiten verschiedener Spielausgänge zu berechnen. KI-gestützte Tipps, die auf statistischen Grundlagen basieren, versprechen eine objektivere Einschätzung als reine Expertenurteile. Verlasse dich auf harte Fakten und Zahlen für deine AI Champions League Tipps. Doch was steckt hinter diesen Zahlen, und wie lassen sie sich sinnvoll interpretieren?
Der Reiz statistischer Vorhersagen liegt in ihrer Nachvollziehbarkeit. Anders als ein Experte, der aus dem Bauch heraus eine Einschätzung abgibt, legt ein statistisches Modell seine Annahmen und Berechnungen offen. Man kann nachvollziehen, welche Daten eingehen, wie sie verarbeitet werden und wie das Ergebnis zustande kommt. Diese Transparenz ermöglicht eine kritische Bewertung und kontinuierliche Verbesserung. Wenn eine Vorhersage danebenliegt, kann man analysieren, woran es lag, und das Modell entsprechend anpassen.
Die Grundlagen statistischer Fußballanalyse
Statistische Methoden für Fußballvorhersagen basieren auf einem einfachen Prinzip: Die Vergangenheit enthält Informationen über die Zukunft. Teams, die in der Vergangenheit viele Tore geschossen haben, werden wahrscheinlich auch in Zukunft viele Tore schießen. Mannschaften, die selten verlieren, werden vermutlich weiterhin schwer zu besiegen sein. Diese Annahmen sind nicht perfekt, aber sie bieten eine solide Grundlage für systematische Vorhersagen.
Der erste Schritt jeder statistischen Analyse besteht in der Datensammlung. Für Champions-League-Spiele stehen umfangreiche Datensätze zur Verfügung, die Ergebnisse, Torschüsse, Ballbesitz, Passgenauigkeit und viele weitere Kennzahlen umfassen. Die Herausforderung liegt nicht im Mangel an Daten, sondern in deren sinnvoller Auswahl und Verarbeitung. Nicht alle Statistiken sind gleich aussagekräftig, und die Kunst besteht darin, die relevanten von den irrelevanten zu trennen.

Die Aggregation von Daten über mehrere Spiele ist ein zentrales Element. Ein einzelnes Spiel hat begrenzte Aussagekraft, weil Zufallsfaktoren eine große Rolle spielen. Ein Team kann ein Spiel haushoch gewinnen, obwohl es schlechter war, oder umgekehrt. Erst über viele Spiele hinweg zeigt sich ein zuverlässiges Bild der tatsächlichen Spielstärke. Statistische Modelle berücksichtigen daher typischerweise die Leistungen über eine gesamte Saison oder zumindest über mehrere Monate.
Die Gewichtung aktueller gegenüber älteren Daten ist ein weiterer wichtiger Aspekt. Rezente Spiele sind informativer als solche, die Monate zurückliegen, weil die aktuelle Form besser widergespiegelt wird. Gleichzeitig sind größere Stichproben statistisch stabiler. Die meisten Modelle verwenden daher einen exponentiellen Abklingfaktor, der neueren Spielen mehr Gewicht gibt, ohne ältere Daten vollständig zu ignorieren.
Die Poisson-Verteilung als Grundlage
Ein klassisches statistisches Werkzeug für Fußballvorhersagen ist die Poisson-Verteilung. Diese mathematische Verteilung beschreibt die Wahrscheinlichkeit, dass eine bestimmte Anzahl von Ereignissen in einem festen Zeitraum auftritt, wenn diese Ereignisse unabhängig voneinander und mit einer konstanten Rate eintreten. Tore in einem Fußballspiel erfüllen diese Bedingungen annähernd, was die Poisson-Verteilung zu einem geeigneten Modell macht.
Die Anwendung ist konzeptionell einfach. Wenn bekannt ist, dass eine Mannschaft im Durchschnitt 1,8 Tore pro Spiel erzielt, kann die Poisson-Verteilung berechnen, wie wahrscheinlich null, eins, zwei, drei oder mehr Tore sind. Die Wahrscheinlichkeit für genau ein Tor beträgt dann etwa 30 Prozent, für zwei Tore etwa 27 Prozent, für drei Tore etwa 16 Prozent und so weiter. Diese Verteilung lässt sich für beide Mannschaften berechnen und kombinieren.
Die Kombination der beiden Torverteilungen liefert Wahrscheinlichkeiten für jedes mögliche Endergebnis. Die Wahrscheinlichkeit für ein 2:1 ergibt sich aus der Multiplikation der Wahrscheinlichkeit, dass die Heimmannschaft genau zwei Tore schießt, mit der Wahrscheinlichkeit, dass die Gastmannschaft genau ein Tor schießt. Die Summierung über alle Ergebnisse mit Heimsieg liefert die Gesamtwahrscheinlichkeit für einen Heimsieg, analog für Unentschieden und Auswärtssieg. Unsere Berechnungen ermöglichen zudem sehr genaue Wahrscheinlichkeits-Tipps für jeden Ausgang.
Diese Methode hat sich als erstaunlich effektiv erwiesen, obwohl sie einige Vereinfachungen vornimmt. Die Annahme, dass Tore unabhängig voneinander fallen, ist nicht ganz korrekt, weil der Spielstand das weitere Spielgeschehen beeinflusst. Eine Mannschaft, die in Führung liegt, verhält sich anders als eine, die zurückliegt. Dennoch liefert die Poisson-Methode brauchbare Schätzungen und bildet die Grundlage vieler fortgeschrittener Modelle.
Die Rolle von Expected Goals in statistischen Modellen
Die Integration von Expected Goals, kurz xG, hat die statistischen Vorhersagen für Fußball erheblich verbessert. Statt nur auf die tatsächlich erzielten Tore zu schauen, berücksichtigen xG-basierte Modelle die Qualität der Torchancen. Ein Team, das viele hochkarätige Chancen herausspielt, aber aus Pech oder mangelnder Effizienz nicht trifft, wird als stärker eingestuft als eines, das aus wenigen Gelegenheiten zufällig Tore erzielt.
Die Verwendung von xG als Eingabevariable für die Poisson-Verteilung ist eine natürliche Erweiterung. Statt die durchschnittlichen Tore pro Spiel zu verwenden, nutzt man die durchschnittlichen xG-Werte. Diese reflektieren die erwartete Torausbeute basierend auf der Chancenqualität und sind weniger anfällig für Zufallsschwankungen. Die resultierende Vorhersage ist typischerweise robuster als eine, die nur auf tatsächlichen Toren basiert.
Die Berücksichtigung der Gegnerqualität ist ein weiterer Vorteil xG-basierter Analysen. Ein hoher xG-Wert gegen einen schwachen Gegner ist weniger beeindruckend als ein moderater Wert gegen einen Spitzenreiter. Fortgeschrittene Modelle adjustieren die xG-Werte entsprechend der Stärke der bisherigen Gegner, um ein realistischeres Bild der tatsächlichen Offensiv- und Defensivstärke zu erhalten.
Die xG-Differenz, also der Unterschied zwischen erwarteten Toren für und gegen ein Team, ist eine besonders aussagekräftige Kennzahl. Teams mit konstant positiver xG-Differenz schaffen mehr hochwertige Chancen als sie zulassen und sind langfristig erfolgreich. Diese Metrik korreliert stark mit dem Punkteschnitt und eignet sich daher gut als Grundlage für Vorhersagen.
Die Elo-Rating-Systeme

Eine weitere statistische Methode für Fußballvorhersagen sind Elo-Rating-Systeme, ursprünglich für Schach entwickelt und später auf den Sport übertragen. Die Grundidee ist einfach: Jedes Team hat eine Bewertungszahl, die seine aktuelle Spielstärke widerspiegelt. Nach jedem Spiel werden die Bewertungen angepasst, wobei der Sieger Punkte gewinnt und der Verlierer Punkte verliert. Die Höhe der Anpassung hängt davon ab, wie überraschend das Ergebnis war.
Wenn ein hoch bewertetes Team gegen ein niedrig bewertetes gewinnt, ist das erwartungsgemäß und führt nur zu einer kleinen Anpassung. Wenn das Außenseiterteam gewinnt, ist das überraschend und führt zu einer größeren Verschiebung. Über viele Spiele hinweg stabilisieren sich die Bewertungen auf Niveaus, die die tatsächlichen Stärkeunterschiede widerspiegeln.
Für Vorhersagen werden die aktuellen Elo-Werte beider Teams verglichen. Die Differenz der Bewertungen lässt sich in eine erwartete Gewinnwahrscheinlichkeit umrechnen. Je größer der Unterschied, desto wahrscheinlicher ist ein Sieg des höher bewerteten Teams. Diese Methode hat den Vorteil, dass sie die gesamte Historie eines Teams in einer einzigen Zahl kondensiert und automatisch für die Qualität der bisherigen Gegner adjustiert.
Anpassungen des klassischen Elo-Systems für Fußball berücksichtigen zusätzliche Faktoren. Der Heimvorteil wird typischerweise durch einen Bonus für die Heimmannschaft modelliert. Die Tordifferenz kann einfließen, um zwischen knappen und deutlichen Siegen zu unterscheiden. Manche Systeme passen die Bewertungen auch für Turnierspiele anders an als für Ligaspiele, um die unterschiedliche Bedeutung zu reflektieren.
Die Regression zur Mitte
Ein zentrales Konzept in der statistischen Fußballanalyse ist die Regression zur Mitte. Dieses Phänomen beschreibt die Tendenz extremer Beobachtungen, bei Wiederholung näher am Durchschnitt zu liegen. Für Vorhersagen hat das wichtige Implikationen, die oft unterschätzt werden.
Ein Team, das in den ersten fünf Spielen der Saison nur Siege eingefahren hat, wird wahrscheinlich nicht alle weiteren Spiele gewinnen. Die perfekte Bilanz enthält vermutlich einen Anteil Glück, der sich im weiteren Verlauf ausgleichen wird. Statistische Modelle berücksichtigen diesen Effekt, indem sie extreme Leistungen in Richtung des langfristigen Erwartungswerts korrigieren.
Die Identifikation von Über- und Unterperformance ist eng mit der Regression zur Mitte verbunden. Wenn ein Team deutlich mehr Tore schießt als seine xG-Werte erwarten lassen, spricht das für eine Überperformance, die sich statistisch korrigieren sollte. Umgekehrt deutet eine Unterperformance auf eine bevorstehende Verbesserung hin. Diese Einsichten können für Prognosen genutzt werden.
Die praktische Umsetzung erfordert allerdings Vorsicht. Nicht jede Abweichung vom Erwarteten ist auf Zufall zurückzuführen. Manche Teams haben tatsächlich überdurchschnittliche Stürmer, die ihre Chancen besser verwerten als der Durchschnitt. Andere haben Torhüter, die mehr Bälle halten, als statistisch zu erwarten wäre. Die Kunst besteht darin, echte Fähigkeiten von zufälligen Schwankungen zu unterscheiden.
Die Berücksichtigung des Heimvorteils
Der Heimvorteil ist einer der am besten dokumentierten Effekte im Fußball. Heimmannschaften gewinnen häufiger als Gastmannschaften, selbst wenn die grundsätzliche Spielstärke berücksichtigt wird. Statistische Modelle müssen diesen Effekt einbeziehen, um akkurate Vorhersagen zu liefern.
Die Quantifizierung des Heimvorteils variiert je nach Liga und Wettbewerb. In manchen Stadien ist der Vorteil besonders ausgeprägt, in anderen weniger. Die Champions League mit ihren internationalen Begegnungen zeigt tendenziell einen geringeren Heimvorteil als nationale Ligen, möglicherweise weil die reisenden Fans einen größeren Anteil ausmachen oder weil die Qualitätsunterschiede zwischen den Teams geringer sind.
Die Modellierung des Heimvorteils kann auf verschiedene Weisen erfolgen. Die einfachste Methode besteht darin, der erwarteten Torzahl der Heimmannschaft einen festen Wert hinzuzufügen und von der der Gastmannschaft abzuziehen. Fortgeschrittene Ansätze erlauben teamspezifische Heimvorteile, die aus den historischen Daten geschätzt werden. Manche Teams sind zu Hause besonders stark, andere zeigen kaum Unterschiede zwischen Heim- und Auswärtsspielen.
Die Entwicklung des Heimvorteils über Zeit ist ein interessantes Phänomen. Studien haben gezeigt, dass der Heimvorteil in vielen Ligen über die Jahre abgenommen hat, möglicherweise aufgrund veränderter Reisebedingungen, professionellerer Vorbereitung oder strikterer Schiedsrichterstandards. Statistische Modelle sollten diese Entwicklung berücksichtigen und ihre Schätzungen entsprechend anpassen.
Die Herausforderungen bei Champions-League-Prognosen
Die Anwendung statistischer Methoden auf die Champions League bringt spezifische Herausforderungen mit sich, die bei nationalen Ligaspielen nicht in gleichem Maße auftreten.
Die Vergleichbarkeit zwischen Ligen ist ein fundamentales Problem. Ein Team, das in der Bundesliga 1,8 xG pro Spiel produziert, ist nicht direkt mit einem Team vergleichbar, das denselben Wert in der portugiesischen Liga erzielt. Das Niveau der Gegner unterscheidet sich, und die Spielstile variieren zwischen den Ligen. Statistische Modelle müssen diese Unterschiede berücksichtigen, was nicht trivial ist.

Die begrenzte Datenbasis für internationale Vergleiche erschwert die Analyse. Teams spielen in der Champions League deutlich weniger Spiele als in ihren nationalen Ligen. Die Stichprobe ist kleiner, was die statistischen Schätzungen unsicherer macht. Ein Team, das in drei Champions-League-Spielen stark aufgetreten ist, hat möglicherweise Glück gehabt, und die kleine Datenmenge erlaubt keine sichere Einschätzung.
Die Anpassung an verschiedene Gegnertypen ist in der Champions League besonders relevant. Manche Teams brillieren gegen bestimmte Spielweisen und tun sich gegen andere schwer. Diese Stilfaktoren sind statistisch schwer zu erfassen, können aber den Ausgang eines Spiels erheblich beeinflussen. Ein defensiv starkes italienisches Team trifft auf ein offensiv ausgerichtetes deutsches, und die historischen Durchschnittswerte beider sind nur bedingt aussagekräftig.
Die erhöhte Bedeutung einzelner Spiele verändert die Dynamik. In der K.O.-Phase gibt es keine zweite Chance, und Teams passen ihr Verhalten entsprechend an. Ein Modell, das auf Ligadaten trainiert wurde, erfasst diese Anpassungen möglicherweise nicht. Die Bereitschaft, Risiken einzugehen oder defensiv zu spielen, variiert je nach Spielstand und Turniersituation.
Die Integration verschiedener Datenquellen
Moderne statistische Modelle für die Champions League integrieren typischerweise verschiedene Datenquellen, um ein umfassenderes Bild zu erhalten. Die Kombination verschiedener Perspektiven kann die Prognosequalität verbessern.
Leistungsdaten aus nationalen Ligen bilden die Grundlage, weil dort die meisten Spiele stattfinden. Die xG-Werte, Elo-Ratings und anderen Kennzahlen werden primär aus Ligaspielen gewonnen und dann auf internationale Begegnungen übertragen. Diese Übertragung erfordert Anpassungen für die unterschiedlichen Wettbewerbsniveaus.
Champions-League-spezifische Daten ergänzen das Bild. Wie hat ein Team in den bisherigen Spielen der aktuellen Saison abgeschnitten? Welche Anpassungen hat es für internationale Begegnungen vorgenommen? Diese Informationen sind besonders wertvoll, weil sie das Verhalten im relevanten Kontext zeigen.
Transfermarktdaten und Kaderbewertungen liefern zusätzliche Perspektiven. Der geschätzte Marktwert eines Kaders korreliert mit der Spielstärke und kann als unabhängiger Indikator dienen. Teams mit teuren Spielern haben tendenziell bessere Chancen, auch wenn Ausnahmen die Regel bestätigen.
Die Gewichtung verschiedener Datenquellen ist eine Kunst für sich. Wie viel Gewicht sollte man den Champions-League-Spielen gegenüber den Ligaspielen geben? Wie stark sollten die Marktwerte einfließen? Diese Entscheidungen beeinflussen die Prognosequalität und erfordern sorgfältige Kalibrierung.
Praktische Anwendung statistischer Tipps
Wer statistische KI-Tipps für die Champions League nutzen möchte, sollte einige praktische Aspekte beachten, um den maximalen Nutzen zu ziehen.
Der Vergleich mit den Marktquoten ist der erste Schritt. Wenn ein statistisches Modell einem Heimsieg eine Wahrscheinlichkeit von 55 Prozent zuweist, entspricht das einer fairen Quote von etwa 1,82. Liegt die angebotene Quote höher, könnte ein Value vorliegen. Liegt sie niedriger, bietet der Markt keinen Vorteil.
Die Berücksichtigung der Modellunsicherheit ist wichtig. Eine Prognose von 55 Prozent bedeutet nicht, dass der Heimsieg sicher ist. In 45 von 100 vergleichbaren Situationen gewinnt die Heimmannschaft nicht. Diese Unsicherheit sollte bei der Einsatzhöhe berücksichtigt werden.
Die Dokumentation der eigenen Wetten ermöglicht langfristige Auswertung. Waren die statistisch identifizierten Values tatsächlich profitabel? Welche Modelltypen haben sich bewährt? Diese Erkenntnisse helfen bei der Verfeinerung der Strategie.
Die Kombination mit anderen Informationsquellen erhöht die Robustheit. Statistische Modelle erfassen nicht alles, und aktuelle Nachrichten, Aufstellungen oder Motivationslagen können zusätzliche Hinweise liefern, die über die Zahlen hinausgehen.
Die Überprüfung der Datenaktualität ist essenziell. Statistische Modelle arbeiten mit den Daten, die ihnen zur Verfügung stehen. Wenn eine wichtige Information, etwa eine kurzfristige Verletzung, noch nicht eingeflossen ist, kann die Prognose verzerrt sein. Ein Blick auf die neuesten Nachrichten sollte jede Wettentscheidung begleiten.
Die Diversifikation über mehrere Spiele kann das Risiko reduzieren. Statt alles auf ein einziges Spiel zu setzen, verteilt man die Einsätze auf mehrere statistisch identifizierte Gelegenheiten. Diese Streuung glättet die Zufallsschwankungen und erhöht die Wahrscheinlichkeit, dass sich der statistische Vorteil langfristig manifestiert.
Die Bewertung verschiedener Wettmärkte
Statistische Modelle liefern nicht nur Prognosen für den Spielausgang, sondern auch für andere Wettmärkte. Die Anwendung auf verschiedene Märkte erfordert jeweils spezifische Anpassungen.
Der Drei-Weg-Markt mit Heimsieg, Unentschieden und Auswärtssieg ist die Grundlage der meisten Analysen. Die Wahrscheinlichkeiten für diese drei Ausgänge ergeben sich direkt aus den Modellberechnungen und lassen sich mit den angebotenen Quoten vergleichen.
Der Über/Unter-Markt für die Toranzahl erfordert eine Analyse der erwarteten Tore beider Teams. Die Summe der xG-Werte oder die Parameter der Poisson-Verteilung liefern die Grundlage für Einschätzungen, ob eher viele oder wenige Tore fallen werden.
Der Markt für Beide Teams treffen lässt sich aus den individuellen Torwahrscheinlichkeiten ableiten. Die Wahrscheinlichkeit, dass beide Mannschaften mindestens ein Tor erzielen, ergibt sich aus der Gegenwahrscheinlichkeit, dass mindestens eine Mannschaft ohne Treffer bleibt.
Handicap-Wetten erfordern Schätzungen der erwarteten Tordifferenz. Ein Modell, das eine durchschnittliche Tordifferenz von 1,3 zugunsten der Heimmannschaft vorhersagt, liefert die Grundlage für die Bewertung verschiedener Handicap-Linien.
Die Grenzen statistischer Vorhersagen
Bei aller Leistungsfähigkeit haben statistische Methoden systematische Grenzen, die man kennen sollte. Die Anerkennung dieser Grenzen ist Teil eines realistischen Umgangs mit Prognosen.
Die inhärente Zufälligkeit des Fußballs lässt sich nicht eliminieren. Selbst perfekte Modelle würden Fehler machen, weil Fußballspiele von Ereignissen abhängen, die nicht vorhersehbar sind. Ein abgefälschter Schuss, ein Pfostentreffer, eine strittige Schiedsrichterentscheidung, all diese Dinge beeinflussen das Ergebnis und entziehen sich der statistischen Erfassung.

Die Vergangenheit ist nicht immer ein guter Prädiktor für die Zukunft. Mannschaften verändern sich durch Transfers, Trainerwechsel oder Formkrisen. Ein Modell, das auf historischen Daten basiert, kann diese Veränderungen nur mit Verzögerung erfassen. Die Annahme der Stabilität ist notwendig, aber nicht immer zutreffend.
Die psychologischen Faktoren werden von statistischen Modellen typischerweise nicht erfasst. Die Bedeutung eines Spiels, der Druck auf einzelne Spieler, die Rivalität zwischen Teams, diese Aspekte können das Ergebnis beeinflussen, lassen sich aber schwer quantifizieren.
Die Überanpassung an historische Daten ist ein technisches Problem, das bei komplexen Modellen auftreten kann. Ein Modell, das perfekt zu den Trainingsdaten passt, versagt möglicherweise bei neuen Daten, weil es zufällige Muster gelernt hat, die sich nicht wiederholen. Die Balance zwischen Modellkomplexität und Generalisierungsfähigkeit ist eine ständige Herausforderung.
Die Kombination verschiedener statistischer Ansätze
Die Praxis hat gezeigt, dass die Kombination verschiedener statistischer Methoden oft bessere Ergebnisse liefert als die Verwendung eines einzelnen Ansatzes. Diese Ensemble-Methoden nutzen die Stärken verschiedener Modelle und gleichen deren Schwächen aus.
Ein typischer Ensemble-Ansatz könnte die Prognosen eines Poisson-Modells, eines Elo-basierten Systems und eines xG-fokussierten Algorithmus kombinieren. Jedes dieser Modelle bringt eine andere Perspektive ein: Das Poisson-Modell fokussiert auf Torverteilungen, das Elo-System auf historische Spielstärke, und der xG-Ansatz auf Chancenqualität. Die gewichtete Durchschnittsbildung ihrer Vorhersagen kann robustere Ergebnisse liefern als jedes einzelne Modell.
Die Gewichtung der verschiedenen Modelle kann statisch oder dynamisch erfolgen. Bei statischer Gewichtung werden feste Anteile verwendet, etwa 40 Prozent für das xG-Modell, 35 Prozent für das Elo-System und 25 Prozent für die Poisson-Methode. Dynamische Ansätze passen die Gewichte basierend auf der jüngsten Performance an: Ein Modell, das in letzter Zeit besser abgeschnitten hat, erhält mehr Gewicht.
Die Validierung von Ensemble-Modellen erfordert sorgfältige Methodik. Die Kombination darf nicht auf denselben Daten optimiert werden, auf denen die Einzelmodelle trainiert wurden, weil das zu Überanpassung führen würde. Kreuzvalidierung und separate Testdatensätze sind notwendig, um die tatsächliche Prognosequalität zu beurteilen.
Die Rolle der Stichprobengröße
Ein oft unterschätzter Aspekt statistischer Analysen betrifft die Stichprobengröße. Die Aussagekraft einer Schätzung hängt direkt davon ab, wie viele Datenpunkte ihr zugrunde liegen.
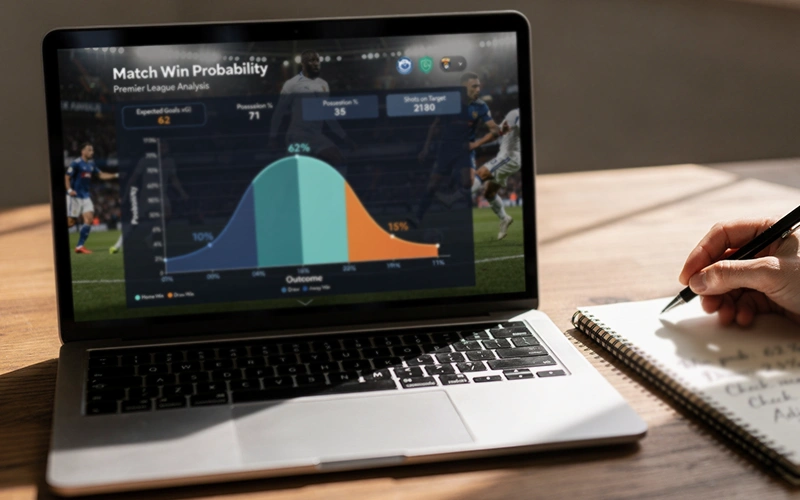
Für ein Team, das 30 Ligaspiele absolviert hat, lassen sich relativ stabile Schätzungen der Spielstärke ableiten. Die Zufallsschwankungen einzelner Spiele gleichen sich über diese Stichprobe hinweg teilweise aus, und das resultierende Bild ist einigermaßen verlässlich. Für ein Team mit nur fünf Champions-League-Spielen ist die Unsicherheit deutlich größer.
Die Berechnung von Konfidenzintervallen macht diese Unsicherheit explizit. Statt zu sagen, dass ein Team eine Siegwahrscheinlichkeit von 55 Prozent hat, könnte man sagen, dass die Wahrscheinlichkeit mit 90-prozentiger Sicherheit zwischen 45 und 65 Prozent liegt. Diese Spanne reflektiert die Unsicherheit aufgrund der begrenzten Datenbasis.
Für die praktische Nutzung bedeutet das: Prognosen für gut dokumentierte Teams aus großen Ligen sind vertrauenswürdiger als solche für Außenseiter mit wenigen internationalen Einsätzen. Die Einsatzhöhe sollte diese Unterschiede in der Konfidenz widerspiegeln.
Die Entwicklung statistischer Modelle über Zeit
Statistische Methoden für Fußballvorhersagen entwickeln sich kontinuierlich weiter. Was vor zehn Jahren als Spitzentechnologie galt, ist heute Standard, und neue Ansätze verschieben die Grenzen des Möglichen.
Die Verfügbarkeit detaillierter Tracking-Daten hat neue Analysemöglichkeiten eröffnet. Wenn die genauen Positionen aller Spieler während des Spiels bekannt sind, lassen sich Metriken berechnen, die über einfache Ereignisdaten hinausgehen. Die Qualität der Raumkontrolle, die Effektivität des Pressings oder die Gefährlichkeit von Laufwegen können quantifiziert werden.
Maschinelles Lernen ermöglicht die Identifikation komplexer Muster, die klassische statistische Methoden nicht erfassen. Neuronale Netze können nichtlineare Zusammenhänge modellieren und aus großen Datensätzen lernen. Allerdings bringen diese Methoden auch neue Herausforderungen mit sich, etwa hinsichtlich der Interpretierbarkeit und der Gefahr der Überanpassung.
Die Demokratisierung von Daten und Werkzeugen macht statistische Analysen einem breiteren Publikum zugänglich. Was früher nur professionellen Analysten zur Verfügung stand, können heute auch interessierte Fans nutzen. Diese Entwicklung verbessert das allgemeine Verständnis und fördert den kritischen Umgang mit Prognosen.
Abschließende Perspektive
Abschließend sei betont, dass statistische Tipps ein Werkzeug sind, das sinnvoll genutzt werden kann, aber keine Garantie für Erfolg bietet. Die Königsklasse bleibt unberechenbar, und kein Algorithmus kann diese Unberechenbarkeit vollständig eliminieren. Wer das versteht und verantwortungsvoll mit seinen Einsätzen umgeht, kann von statistischen Analysen profitieren, ohne sich unrealistischen Hoffnungen hinzugeben.
Die Champions League bietet Jahr für Jahr Momente, die keine Statistik vorhersagen konnte. Das späte Tor in der Nachspielzeit, die taktische Überraschung, die individuelle Brillanz, diese Elemente machen den Fußball so faszinierend. Statistische Methoden können helfen, die Wahrscheinlichkeiten besser einzuschätzen, aber sie können die Magie des Spiels nicht erfassen. Und vielleicht ist das auch gut so.